핀바이브 (Finvibe) - AI 가상 투자 및 학습 플랫폼
2025.12 – 현재백엔드 개발 파트장 | Finvibe 팀 (백엔드 개발팀 3명)
Modular Monolith · Domain-Driven Design(DDD) · WebSocket · Virtual Thread · Redis Pub/Sub · B+ Tree Index
실제 금융 시장 환경을 실시간으로 반영하는 10만 MAU 대응 목표의 모의 투자 플랫폼입니다. 프로젝트 초기 도메인 설계부터 운영 환경에 맞춘 인프라 구조 개편까지 전체 백엔드 아키텍처 구축을 담당했습니다.
Java
Spring Boot
JPA
Spring Cloud
Docker
Kubernetes
Cloudflare
Kong API Gateway
MySQL(MariaDB)
Redis
Kafka
GitHub Actions
Argo CD
Prometheus
Grafana
아키텍처 설계 내역
1차 설계 - 기능 결합도 완화를 위한 DDD 및 모듈러 모놀리스(Modular Monolith) 도입
앱 내에 AI 챌린지, XP 보상, 랭킹 등 다수의 비즈니스 로직이 혼재되어 상호 결합도가 높아지는 문제가 예상되었습니다. 이를 해결하고자 DDD(도메인 주도 설계)를 채택하여 이벤트 스토밍을 통해 바운디드 컨텍스트를 식별했습니다.
- 이벤트 주도 아키텍처(EDA) 적용: 컨텍스트 간 데이터 통신을 Kafka 기반 도메인 이벤트로 대체하여 비즈니스 로직의 결합도를 낮추고 기능 개발 리드타임을 단축했습니다.
- 굵은 입자 서비스 적용: 무조건적인 마이크로서비스 확장은 배제하고, 식별된 컨텍스트 모듈들을 하나의 인스턴스 안에서 격리하여 동작시키는 모듈러 모놀리스 구조를 구성하여 배포 프로세스를 단순화했습니다.

실제 오프라인 이벤트 스토밍 진행 모습
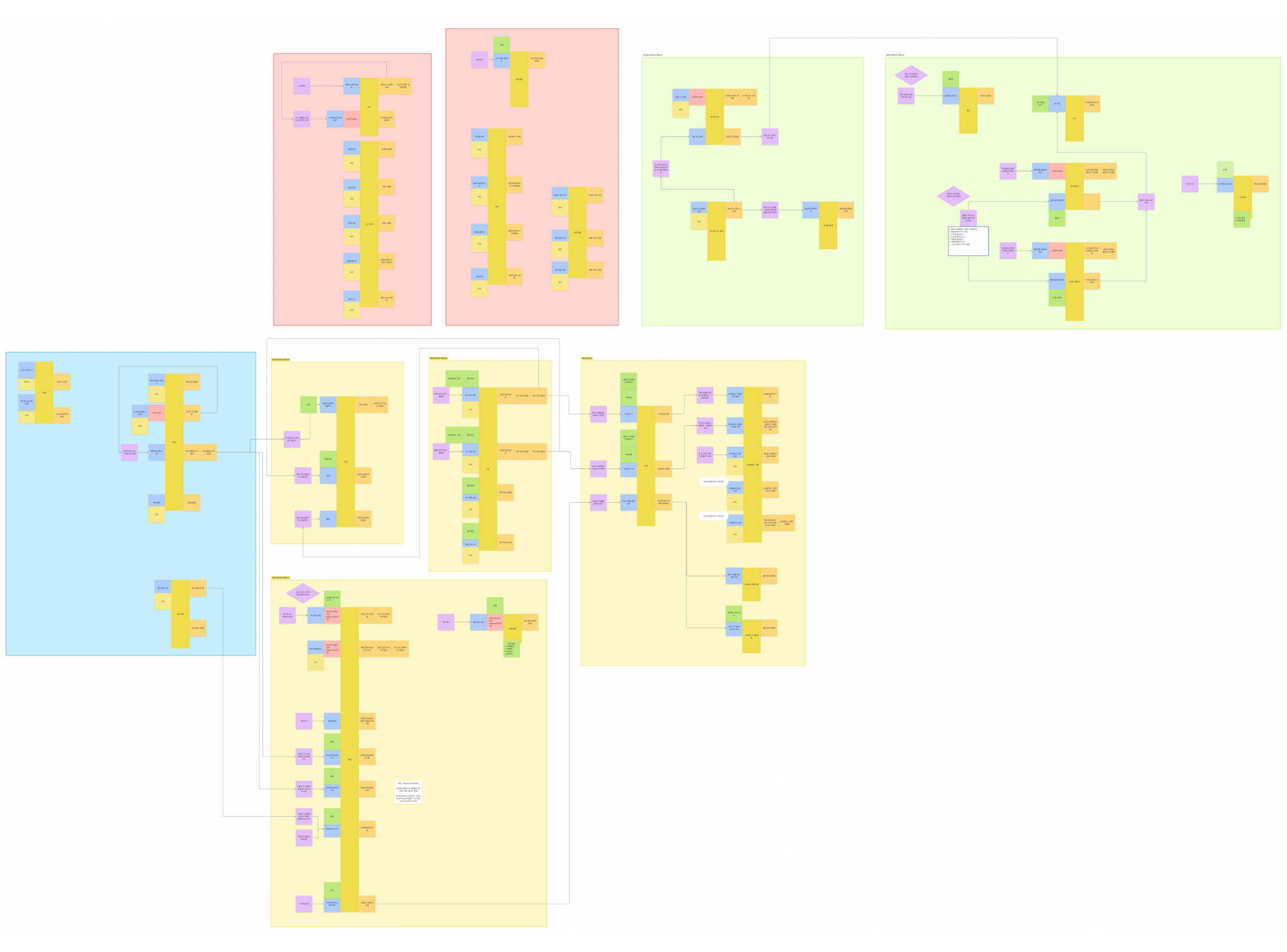
도메인 이벤트 및 바운더리 식별 결과
↓
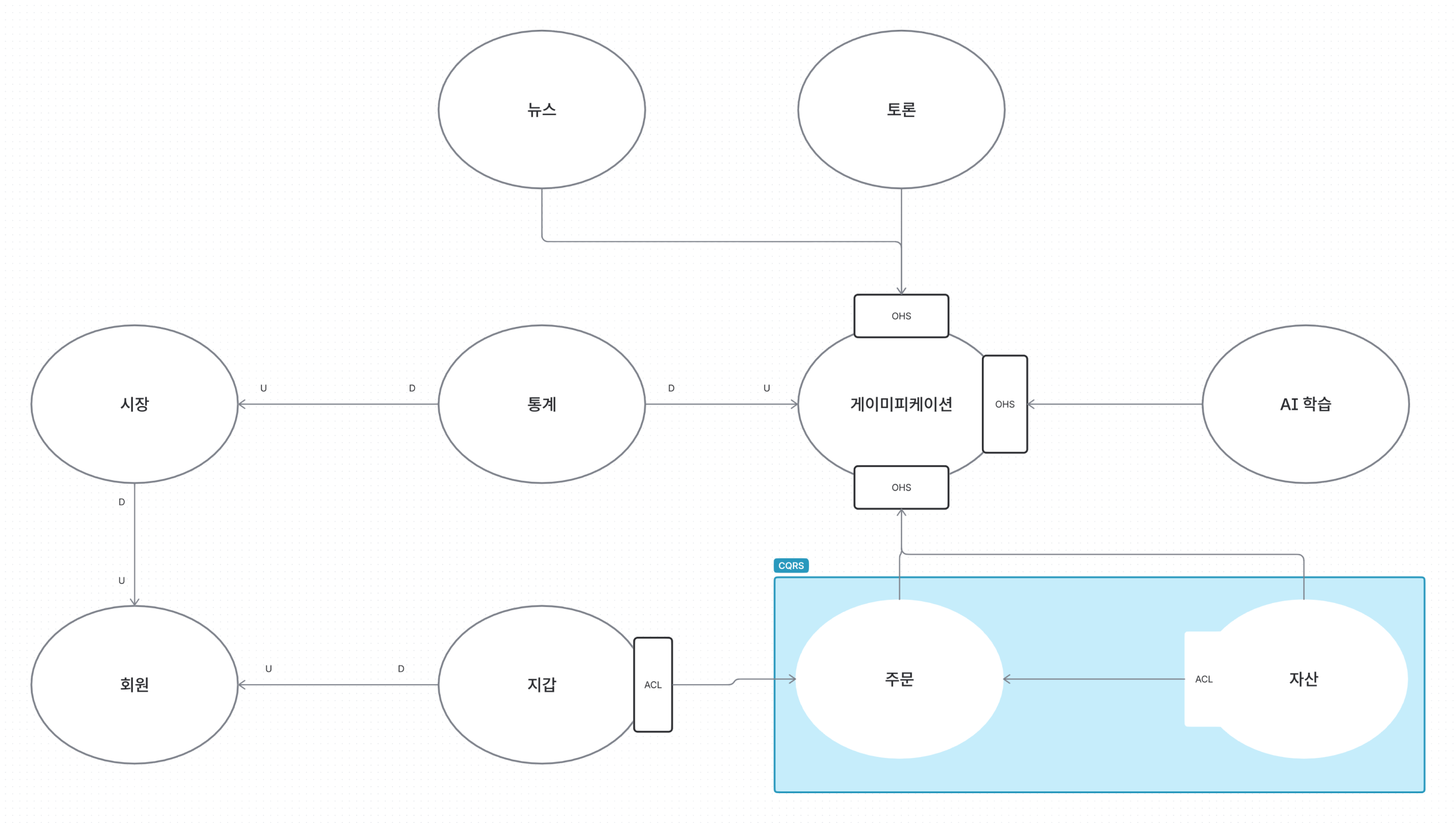
바운더리 컨텍스트 및 컨텍스트간 관계 식별

전술적 설계 : 애그리거트 패턴 기반 모델링
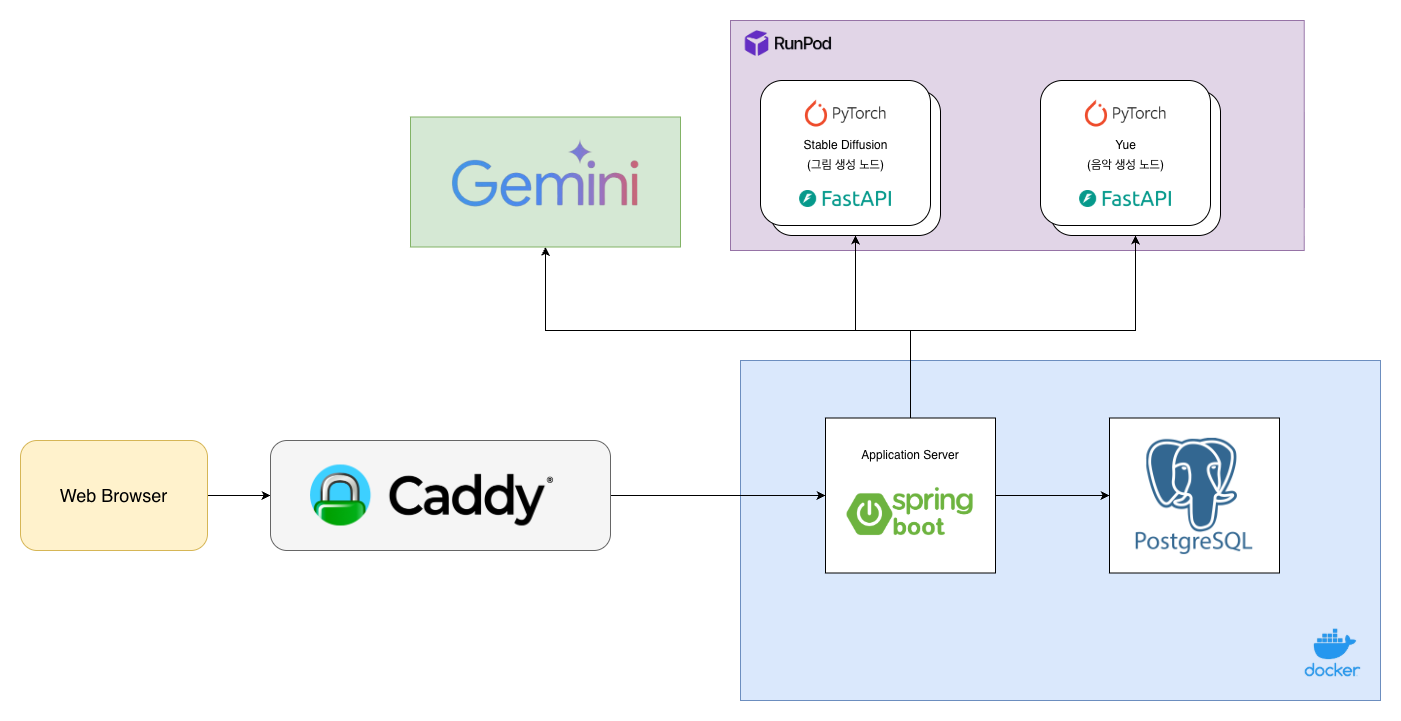
초기 시스템 아키텍처 다이어그램
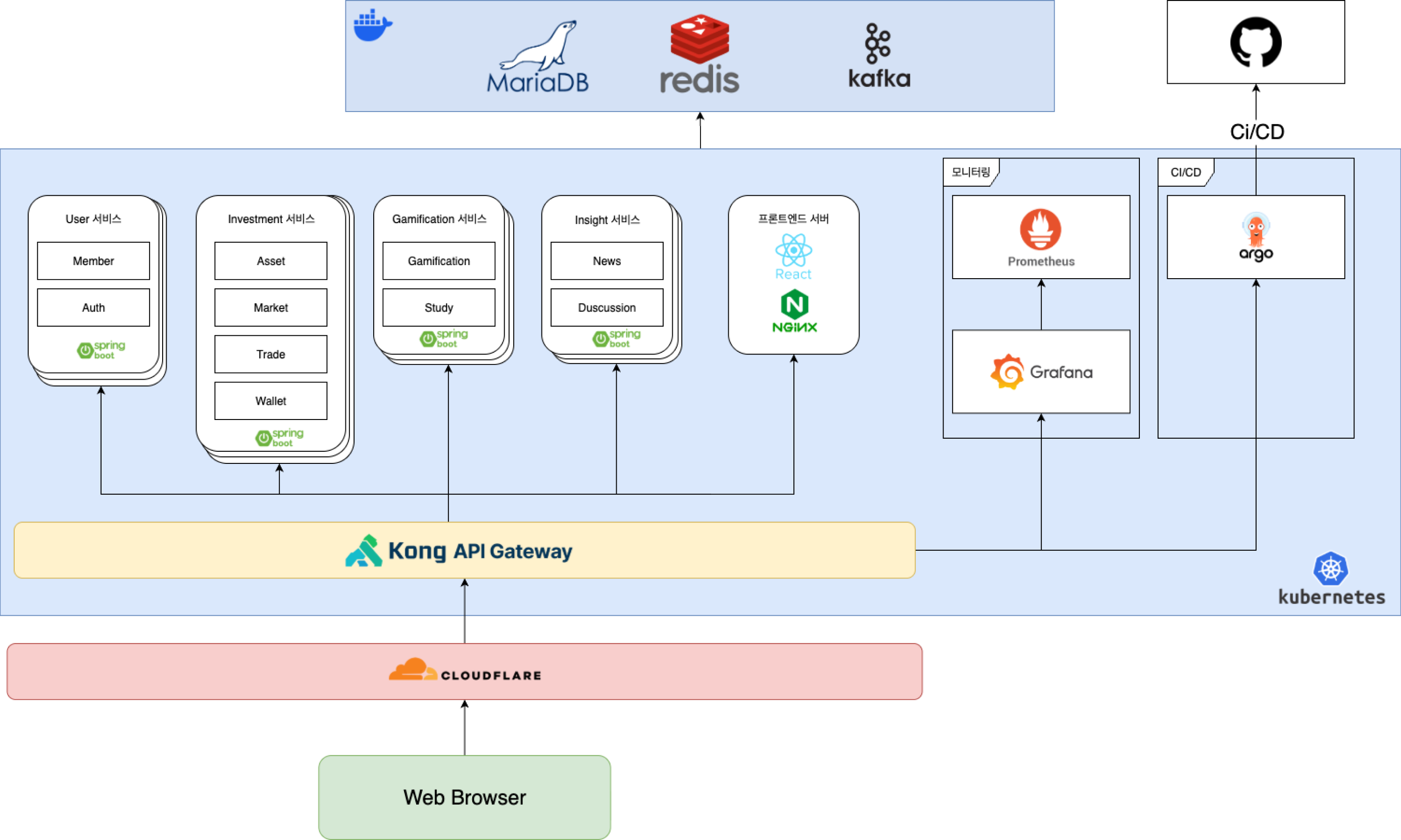
2차 설계(리팩토링) - 분산 오버헤드 제어 및 기능 중심(Scale-Out) 아키텍처 개편
소규모 팀 환경에서 도메인 단위로 개별 인스턴스를 유지 및 확장하는 것은 불필요한 인프라 및 운영 오버헤드를 발생시켰습니다. 이에 따라 도메인 모듈 경계는 유지하되, 도메인 중심 분산에서 기능 중심 분산으로 아키텍처를 개편했습니다.
- 손쉬운 인스턴스 병합: 기존 시스템이 모듈러 모놀리스 기반으로 느슨하게 결합되어 있었기에, 복수의 도메인 모듈을 단일 메인 API 인스턴스로 안전하고 빠르게 통합할 수 있었습니다.
- 선택적 Scale-Out을 통한 트래픽 대응: 대규모 트래픽 부하 분산이 필수적인 웹소켓 리스너와 배치(Batch) 서비스 레이어만을 별도의 외부 인스턴스로 분리 배치하여, 전체 인프라 비용을 절감하면서 동시 접속 수용 능력을 극대화했습니다.
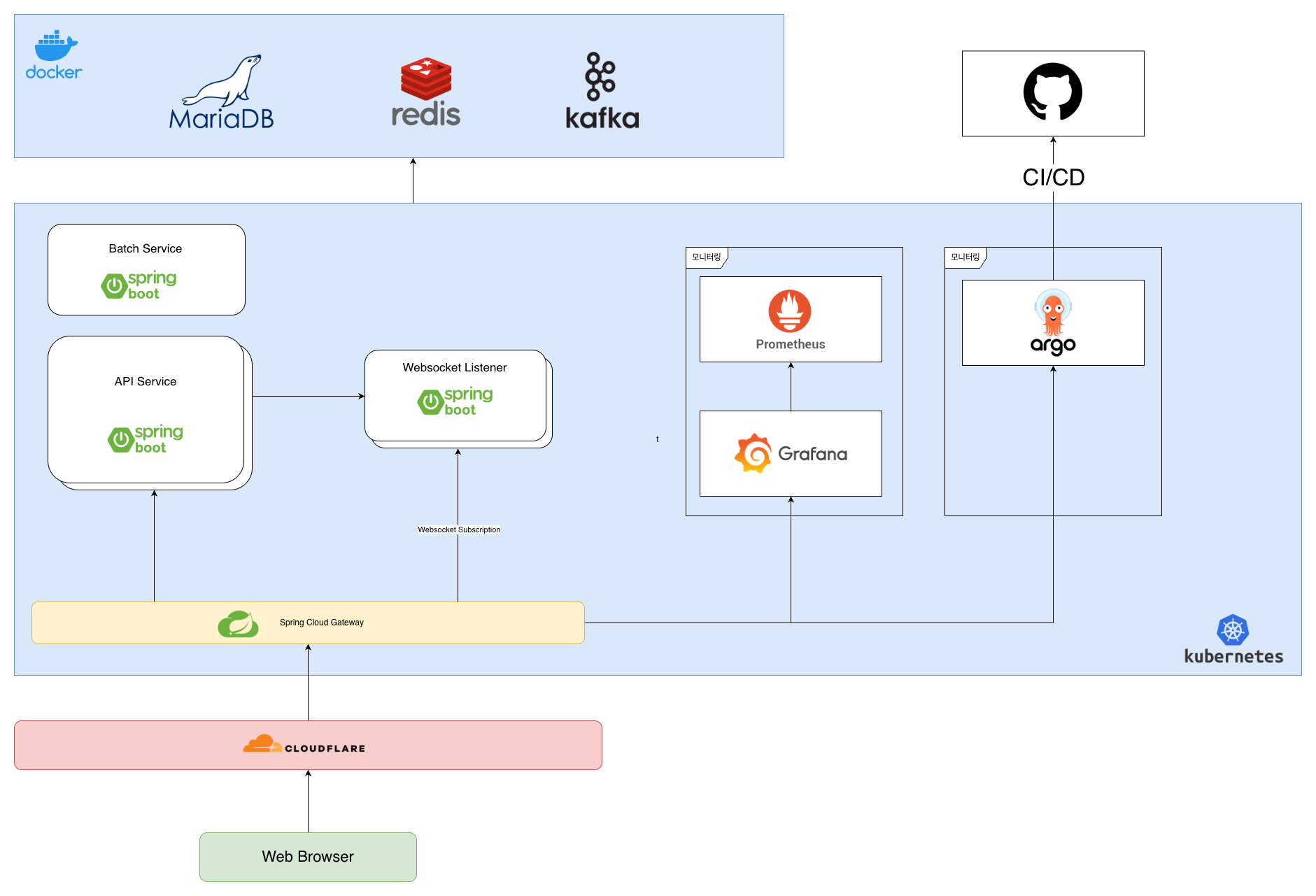
웹소켓 및 배치 스케줄러를 분리한 실용적 스케일 아웃 아키텍처
수행한 문제 해결
고부하 시나리오의 웹소켓 동시 연결 병목 개선
-
Situation10만 MAU 운영 시나리오를 가정한 상태에서 초단위 실시간 호가를 전송해야 했습니다. 최초 K6 부하 테스트 결과, 약 5,000건의 동시 커넥션에서 Out Of Memory(OOM)가 발생하고 데이터 Fanout(전파) 꼬리 지연 시간이 20초를 초과(p99 > 20s)하는 중대한 병목에 직면했습니다.
-
TaskOOM의 원인이 되는 메시지 버퍼 누수 구간을 식별하고, 트래픽에 맞춰 선형적 Scale-Out이 가능하도록 서빙 환경을 개편하여 '동시 접속 2만 커넥션' 동기화 목표를 달성해야 했습니다.
-
Action메모리 힙 덤프 분석을 통해 Fanout 처리 지연으로 적재된 메시지가 힙 메모리(3GB)를 고갈시킴을 확인했습니다. Fanout 처리에 Virtual Thread를 도입하여 병렬 처리 및 Context Switch 비용을 최적화했습니다. 또한 웹소켓 리스너를 분리하여 외부 인스턴스로 분산 배치하고, 동시성 환경에서의 메시지 순서를 보장하기 위해 세션별 Inbound Task Queue와 Redis Pub/Sub 연동 비동기 통신 구조를 설계했습니다.
-
Result시나리오 목표치인 2만 동시 접속 커넥션을 달성하였고, 트래픽 스파이크 하에서 Fanout 지연 시간(p55 및 p99)을 1초 이내로 안정화했습니다.Trade-off: Redis Pub/Sub 구조 도입으로 인해 단일 노드 메모리 방식보다 필연적인 네트워크 I/O 비용이 추가되었으며, 메시지 순서 보장용 Inbound Queue 할당으로 인해 활성 세션별 로컬 메모리 점유율이 소폭 상승했습니다.
[ Before & After 성능 지표 비교 ]

[ Before ] 개선 전 웹소켓 병목 지표. Fanout Timing이 20초 가까이 걸림

[ After ] Virtual Thread Fanout 적용 후
유저 PK 타입이 UUID일 경우의 B+ Tree 인덱스 성능 개선
-
Situation시스템 보안 목적으로 외부 노출 유저 식별자(PK)를 UUIDv4로 설계한 후 테스트 과정에서, 유저 테이블 연관 쿼리 실행 시 높은 Disk I/O 및 지연 현상을 식별했습니다.
-
Task문제의 원인을 B+ Tree 인덱스에 무작위 값이 삽입될 때 발생하는 페이지 파편화(Page Split) 및 물리적 Locality 저하로 판단하고, 관련 조회 성능 개선과 스토리지 낭비 방지 방안이 필요했습니다.
-
Action내부 데이터 Join 및 스캔에는 순차적 Auto-Increment 특성을 지닌 숫자형 PK(BIGINT)를 사용하고, 외부 API 통신 식별자로는 논리적 PK(UUID)를 매핑하는 이중 키(Dual-Key) 식별 구조로 재설계했습니다. 데이터베이스 접근 오버헤드를 줄이기 위해 두 식별키 간의 매핑 테이블은 Redis에 캐싱하여 Disk I/O를 제어했습니다.
-
Result클러스터드 인덱스의 Locality를 복구하여 인덱스 스토리지 공간을 절감하고, 범위 조회 시 탐색 Page 접근 횟수를 33% 감소시켰습니다. 외부 식별 보안성을 유지하면서 Join 쿼리 평균 응답 속도를 최대 30% 개선했습니다.Trade-off: B+ Tree 탐색 성능은 극대화되었으나, 이중 구조(Dual-Key)를 연결하는 UUID-BIGINT 매핑 정보를 Redis에 추가로 동기화해야 하므로 데이터 정합성 관리 복잡도와 캐시 의존성이 고질적으로 증가했습니다.